


布隆过滤器 BloomFilter
1.前言
“去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比较大。
去重需要考虑两个点:去重的数据量、去重速度。为了保持较快的去重速度,一般选择在内存中进行去重。数据量不大时,可以直接放在内存里面进行去重,例如python可以使用set()进行去重。当去重数据需要持久化时可以使用redis的set。当数据量再大一点时,可以用不同的[加密算法](https://so.csdn.net/so/search?q=加密算法&spm=1001.2101.3001.7020)先将长字符串压缩成16/32/40个字符,再使用上面两种方法去重;当数据量达到亿(甚至十亿、百亿)数量级时,内存有限,必须用“位”来去重,才能够满足需求。Bloomfilter就是将去重对象映射到几个内存“位”,通过几个位的0/1值来判断一个对象是否已经存在。然而Bloomfilter运行在一台机器的内存上,不方便持久化(机器down掉就什么都没啦),也不方便分布式爬虫的统一去重。如果可以在Redis上申请内存进行Bloomfilter,以上两个问题就都能解决了。
2.布隆过滤器使用场景
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
3.简介
通过较少的空间,不存储数据本身而存储通过hash函数映射的位向量表,以此作为判断一个值是否存在的依据。BloomFilter只能确保一个值一定不存在,判断存在的情况由于位向量表有限以及hash表也可能产生冲突,并不准确,有一定误判的几率。
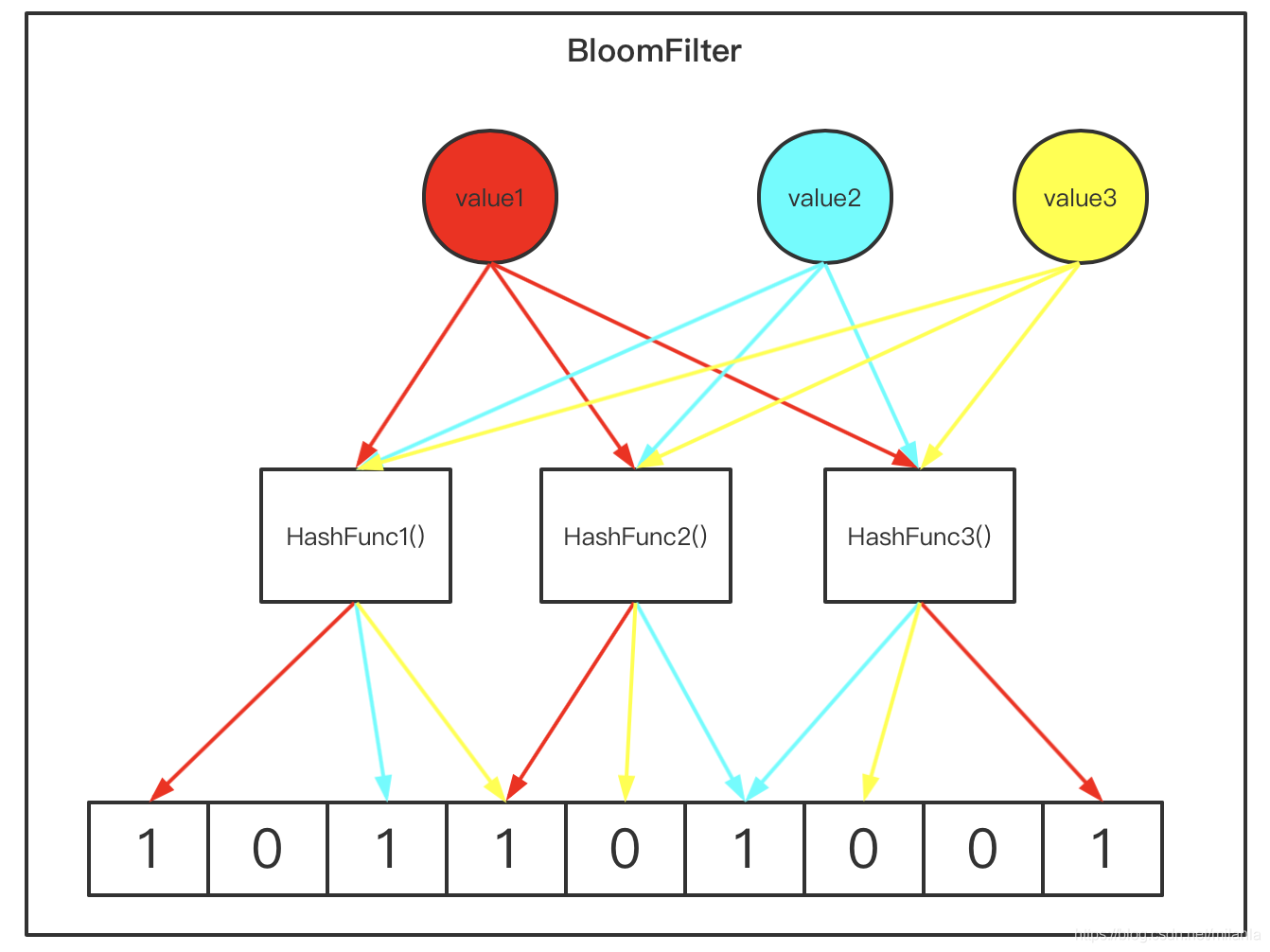
这时如果再有一个新的元素x,我们要判断它是否属于S集合,便会将仍然用&个散列函数对x求映射结果,如果所有结果对应的位数组位置均为1,那么就认为x属于S集合,否则工不属于S集合。
## 4.**布隆过滤器的算法总结:**
1.初始化时,需要一个长度为n比特的数组,每个比特位初始化为0;
2.然后需要准备k个hash函数,每个函数可以把key散列成为1个整数;
3.某个key加入集合时,用k个hash函数计算出k个散列值,并把bit数组中对应的比特位置为1;
4.判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果有比特位是0,则该key一定不在集合中。
优点:数据结构是高效且性能很好的
缺点:是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。删除可能会影响到其他元元素判断结果
4.在scrapy中安装使用
pip install scrapy-redis-bloomfilter在settings配置文件增加配置如下:
# # # 分布式爬虫配置 <-----
REDIS_HOST = '0.0.0.0'
REDIS_PORT = 6378
REDIS_PARAMS = {'password': '***', 'db': ***}
# #
# # 去重组件 scrapy_redis 实现的一个去重方案
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# SCHEDULER 修改调度器 把任务分发的逻辑跌给服务器
# 默认的调度器是在本地调度,
SCHEDULER = "scrapy_redis_bloomfilter.scheduler.Scheduler"
# 开启数据持久化(把爬取过的数据给保存下载)
SCHEDULER_PERSIST = True
BLOOMFILTER_HASH_NUMBER = 6
# Bit
BLOOMFILTER_BIT = 32 # 512M # 4,294,967,296位注:需要将spider文件中的dont_filter改为True,默认为True
崔大神ScrapyRedisBloomFilter源码地址:
评论区